X-Robots-Tag vs. Meta Robots Tag: What’s the Real Difference for SEO?

Before websites are ranked and displayed on search results, they are first crawled and indexed by search engine bots. But how do they know to do that? They are instructed by these two components: the x-robots tag & meta robots tag. Between a comparison of x-robots-tag vs meta robots, the former is included in the HTML header of the URL, whereas the latter is found in the web page’s HTML code.
Even though both aid in instructing search engine bots to crawl and index sites, they have their differences and unique advantages. Understanding those nuances and knowing when to leverage each is imperative for SEO success. Along with proper robots txt optimization, using these tags ensures search engines get the right crawling signals. Addressing potential crawling issues in GSC is easier when these tags are correctly implemented, as search engines can more accurately index your content. Let’s discuss more about these essential components by understanding the difference between x-robots-tag and meta robots and how you can effectively leverage them to achieve SEO dominance.

Defining Robots Meta Tag and the X-Robots-Tag
Robots Meta Tags are HTML elements that tell search engine crawlers how they should crawl and index specific webpages of a site. They are placed within the <head> section of the HTML code, and they allow you to control specific aspects of a page’s online visibility and behavior in the SERPs. These tags are a key part of meta tags for SEO, as they directly impact how your site appears and performs in search engines. The syntax is highlighted in green in the image below:

In the above screenshot, the robots meta tag is instructing search engine crawlers not to index and display the specific web content. Now, coming to X-Robots-Tag, it is an HTTP response header that is used to control how search engine crawlers crawl and index specific parts of the webpage. They are added in the HTTP header of a response, which means that it’s sent before the actual content of the page.

Despite sharing similarities with the meta robots tag, these work outside of the HTML documents, making it ideal for non-HTML files like PDFs, images, videos, or even entire sets of URLs. Both robots meta tag and X-Robots-Tag give website owners granular control over the web content by signalling search engines to index only the most relevant content and ensure that the viability is at an all-time high. Mastering meta tag optimization helps you implement these instructions efficiently and in alignment with your SEO goals.
Understanding the difference between x-robots-tag and meta robots
Now that you have a brief idea about the two concepts, let’s dive in further and learn how they differ in terms of functionalities and use case scenarios.
When to use robots meta tag
- Prevent search engines from indexing duplicate content
- Prevent webpages from being shown irrelevant to search results
- Avoid webpages from being cached if they contain sensitive data
If you take a look at the syntax of the meta robots tag, it consists of two attributes: name and content. The name attribute, often referred to as a User Agent, specifies which crawlers should follow the instructions provided in the content attribute. When it comes to the content attribute, it is used to specify the directives that search engine crawlers must follow when indexing or crawling a web page. These content attributes, known as values, can be used both in the robots meta tag and X-Robots-Tag.
Let’s look at some of the robots meta tag and X-Robots-Tag examples:
- noindex: Explicitly used to prevent indexing webpages.
Examples:
<meta name=”robots” content=” noindex”>
X-Robots-Tag: noindex
- nofollow: Signals not to follow links.
Examples:
<meta name=”googlebot” content=”nofollow”>
X-Robots-Tag: googlebot: nofollow
- notranslate: Avoids translating a webpage’s content to maintain the original language and context.
- nosnippet: When implemented, search engines won’t display snippet results.
- max-image-preview: [setting]: Similar to the snippet attribute, this one specifies the maximum image preview size that can be displayed in search results.
- noimageindex: Used to signal search engines not to index any images on a webpage.
The above meta tags can be combined together to create multi-rule directives that allow achieving more than one result at the same time. An example of this is shown below:
<meta name=”robots” content=”noindex, nofollow”>
When to use x-robots-tag
The X-Robots-Tag usage is similar to the meta robots tag. However, there are certain advantages where X-Robots Tag remains superior over the other.
Control Non-HTML Files
While meta robots tag only crawls and indexed HTML page assets, X-Robots-Tag can be used to control the crawling and indexing of non-HTML assets such as PDF, images, videos, etc.
Site-Wide Directives
With the X-Robots-Tag, you can set directives that apply to the entire section of the website or specific file types.
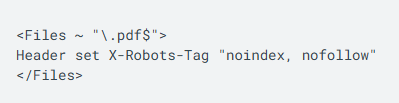
If you are thinking how to apply the X-Robots-Tag, it is possible to add it to a site’s HTTP header through the configuration files of your site’s web server software. On Apache, you can add the tag by using .htaccess and httpd.conf files. Let’s consider an example in which you want to instruct the X-Robots-Tag to not follow and index the PDF files across an entire site. This should be implemented something like below:
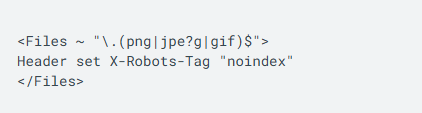
You can use the X-Robots-Tag for non-HTML assets using robots meta tags isn’t possible. The example below shows creating a noindex rule using the X-Robots-Tag for image files across a site.
X-Robots-Tag vs Robots.txt: Similar but different
Understanding the difference between x-robots-tag and meta robots is crucial because it determines how precisely you can control the indexing and the crawling process. As you learn more about it, you might confuse X-Robots-Tag with Robots.txt. The latter is a text file that is located within the root directory of a website. Its primary purpose is to tell search engine crawlers which parts of the site they can access and crawl.
Whereas X-Robots-Tag and meta robots tag are implemented to instruct search engine bots on crawling and indexing specific webpages of a site. X-Robots-Tag in particular can dictate how to handle non-HTML files, which is something the robots.txt file cannot do. The key is to understand the difference between x-robots-tag and meta robots and x-robots-tag vs robots.txt, and use them strategically to control website accessibility and search engine behaviour.
X-Robots-Tag vs Meta Robots Mistakes To Avoid
As you do a X-Robots-Tag vs. meta robots tag comparison, there are several mistakes that can occur if not careful with your approach. It is essential to watch out for them as they can impact your SEO badly. Here, we have listed some of them so that you can avoid them:
Implementing Noindex on crucial pages
The purpose of noindex is to prevent crawlers from indexing specific pages. However, adding it for the most important pages, such as the Homepage, service/landing pages, prevents search engines from indexing and displaying them on search results.
Not implementing X-Robots-Tag for Non-HTML Files
If your website has non-HTML files and you don’t want them to be indexed, implementing X-Robots-Tag is necessary. Forgetting to add that results in those files being indexed by search engines.
Presence of Conflicting Directives
If there are conflicting instructions in both the Meta Robots Tag and X-Robots-Tag for the same page, this confuses search engine crawlers and results in improper indexing.
Ignoring Search Engine Guidelines
Google’s guidelines on crawling and indexing get updated from time to time. Not keeping up with these changes leads to mistakes in instructing the robots.
Winding Up
When it comes to X-Robots-Tag vs. meta robots tag, the one question remains: do you need both for the crawling and indexing process? The answer to that is to use whichever method works best for your scenario. The point is that search engines follow your index instructions, whether you use any one of them. Both x-robots-tag vs meta robots are essential tools for guiding search engine crawlers on how to interact with your web content.
The main difference lies in their implementation method. While the meta robots tags are added in the head of the HTML code, X-Robots-Tags are placed within the HTTP header response. Knowing about X-Robots-Tag vs Meta Robots allows you to have precise control over what content is indexed and displayed by search engines. With guidance from an expert search engine optimization company, you can ensure that your site is both searchable and strategically visible.
Related Post
Publications, Insights & News from GTECH